

11月24日晚上7点,网赌-网赌app
语言大数据与计算人文中心特邀苏州大学计算机学院的李正华教授,围绕“大模型时代的研究成果、思考与建议”的主题展开报告。报告由网赌
李斌教授主持,山西大学谭红叶教授以及多所学校的师生约80人参加了研讨。
李正华教授展示了其团队在大模型应用于自然语言处理(NLP)方面取得的显著进展,分享了如何在大模型蓬勃发展的背景下平衡学术价值与实际应用,开展特色研究,为该领域的研究与实践提供了诸多启示。
一、研究成果概述:
李正华教授团队的研究成果涉及基于大语言模型(LLMs)的中文拼写纠错(Chinese Spelling Correction, CSC)与文本纠错(Grammatical Error Correction, GEC)任务。报告中,李教授详尽阐述了两项工作的基本原理、方法、贡献并展望了未来的研究方向。
他指出,EMP2024的特点在于其“training-free”和”prompt-free”的设计,基于大模型且无需训练。该模型能够避免大语言模型出现的过度修改问题(例如将不必要的词汇修改成不相关的内容),从而提高拼写纠错的精确度。该方法在多个标准数据集上取得了优异结果,尤其在领域泛化性方面表现优异。
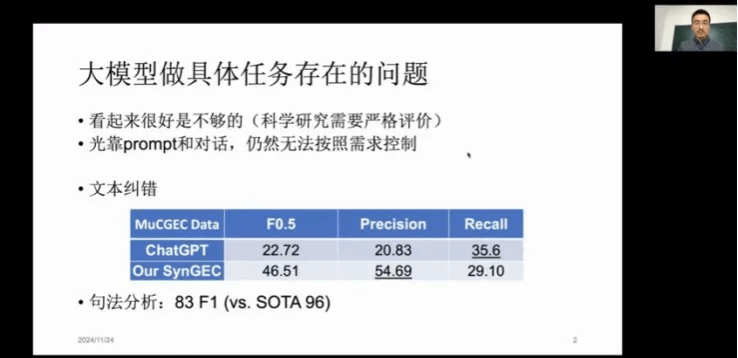
李教授还介绍了他们在语法错误纠正(GEC)任务中的工作。该方法通过大模型对小模型进行干预,有效提升了文本纠错任务中的精确度与召回率,尤其在处理复杂错误(如词序错误、冗余词删除)时具有明显优势,具有较强的应用前景。

二、大模型时代科研的思考与建议:
李正华教授的研究充分展示了大语言模型在实际应用中的潜力和局限性。尽管大模型在多种任务中展示了强大的能力,但在科研领域,严格的任务定义和模型评价标准依然至关重要。
关于大语言模型的本质与影响,李教授提出了几点新的认识。他指出强化学习并非大模型质变的主因,其强大的语言生成能力主要源于大规模参数量和高质量数据。同时,他认为大模型带来的积极变化在于知识库构建与任务设计等方面。大模型可参与知识库构建,如提供顶层设计、推荐示例、收集和初步标注数据等,有助于提出新任务,且能在少量标注的情况下开展任务,节省人力物力。
针对任务定义与研究方向,李教授提出了建议。首先,重新审视任务定义,结合大模型评测,思考现有句法语义表示的合理性,拓宽建模思路,尝试更难、更真实且重要的问题,将大模型作为工具或试金石。其次,持续完善数据集,提高标注质量,丰富参考内容,尤其在大模型时代,可利用大模型辅助标注工作,解决如文本纠错任务中数据集参考不足导致模型性能评估不准确的问题。
李教授还表明了自己对大模型相关研究方向的探索和尝试。一是尝试从大模型中萃取知识构建知识库,同时深入思考大模型对语言的理解程度及评测方式。二是句法分析相关工作,包括句法表示的优化、利用大模型进行句法分析及大模型与小模型融合辅助句法分析等,探索大模型在句法分析领域的应用边界及效果提升途径。
最后,李教授表达了对人工数据标注和评价的看法。他认为,人工评价模型结果的过程即数据标注,两者紧密相关,并举例说明了提高标注质量的方法在于细致标注、多人标注、局部与有选择标注。
李正华教授的报告不仅展示了团队在大模型时代 NLP 研究中的创新成果,更在大模型本质、研究方向、科研实践以及数据标注等多方面提供了全面而深入的思考与建议,对推动该领域研究发展和指导研究生科研具有重要意义。
在最后的问答环节,李正华教授就大语言模型时代如何进行语言数据标注、语言技术评测等问题解答了听众的诸多问题。讲座在热烈的掌声中结束。
